
In this article I will explain why Dispatchers.Default and Dispatchers.IO, which are the standard background dispatchers provided with Kotlin Coroutines framework, aren’t really that useful for aything, really.
Please keep in mind that the argument I’m going to make here is limited to JVM ecosystem (including Android).
Preface
I suspect that, at this point, you might already be skeptical of the premise of this article, or even think that I’m out of my mind. That’s a reasonable reaction. After all, the official documentation recommends Dispatchers.Default and Dispatchers.IO for background work, countless posts repeat this recommendation and these dispatchers have already been used for years in many projects. Calling something as prevalent as that an anti-pattern is a bold statement. I agree.
However, in fact, the argument I’m going to make in this post is even more outrageous than that.
See, RxJava, concurrency framework which used to be the hottest thing in Android world at some point (that’s not a compliment), employs a similar strategy. It provides a pair of Scheduler objects, Schedulers.computation() and Schedulers.io(), which are very similar in their properties and use cases to Dispatchers.Default and Dispatchers.IO, respectively. Therefore, by arguing that standard background dispatchers in Coroutines framework are anti-pattern, I also claim that RxJava’s standard background schedulers are anti-pattern.
I fully understand that I stick my neck out by writing this article. However, I’ve been thinking about this issue for the past year and I’m confident that it deserves to be discussed. I’m also sure that this post will allow many readers to get a deeper insight into the world of concurrent code optimizations, which is very interesting and advanced topic.
Dispatchers.Default and Dispatchers.IO
Let’s review the documentation of the standard background dispatchers and understand what it does and, more importantly, what it doesn’t say.
Documentation for Dispatchers.Default states:
The default CoroutineDispatcher that is used by all standard builders like launch, async, etc if neither a dispatcher nor any other ContinuationInterceptor is specified in their context.
It is backed by a shared pool of threads on JVM. By default, the maximum number of threads used by this dispatcher is equal to the number of CPU cores, but is at least two.
Please note that the docs don’t say anything about the use cases for this dispatcher. In fact, I couldn’t find the guidelines for its usage anywhere in the official Kotlin documentation. Therefore, as far as I can see, there is no formal basis for the widespread claim that Dispatchers.Default should be used for CPU-intensive tasks. That alone is a big red flag.
Furthermore, why this dispatcher is backed by two threads on devices with just one CPU core, but the number of threads is equal to the number of CPU cores otherwise? It looks like there is some issue with having just one thread, but, so far, I couldn’t find any information about it. I don’t think it’s a big problem on its own, but, as you’ll see a bit later, there is something off about the choice of numbers of threads in Dispatchers.IO. Therefore, this unexplained corner case in Dispatchers.Default contributes to the overall impression of “something isn’t right”.
So, in practice, all you can derive from the official documentation of Dispatchers.Default is that this dispatcher will be used if you don’t specify another one. That’s all.
Documentation for Dispatchers.IO states:
Platform and version requirements: JVM
The CoroutineDispatcher that is designed for offloading blocking IO tasks to a shared pool of threads.
Additional threads in this pool are created and are shutdown on demand. The number of threads used by tasks in this dispatcher is limited by the value of “kotlinx.coroutines.io.parallelism” (IO_PARALLELISM_PROPERTY_NAME) system property. It defaults to the limit of 64 threads or the number of cores (whichever is larger).
Moreover, the maximum configurable number of threads is capped by thekotlinx.coroutines.scheduler.max.pool.sizesystem property. If you need a higher number of parallel threads, you should use a custom dispatcher backed by your own thread pool.
Implementation note
This dispatcher shares threads with a Default dispatcher, so usingwithContext(Dispatchers.IO) { ... }does not lead to an actual switching to another thread — typically execution continues in the same thread. As a result of thread sharing, more than 64 (default parallelism) threads can be created (but not used) during operations over IO dispatcher.
This dispatcher is exclusive to JVM and, according to the docs, it was designed to offload blocking IO tasks to a shared pool of threads. Sounds kind of reasonable, until you read further.
Dispatchers.IO is limited to 64 threads, or the number of cores by default. This immediately raises the question: why this specific number? Furthermore, given the vast differences in IO load profiles between different JVM targets (e.g. Android vs backend), it’s obvious that this number, even if accidentally optimal for one target, might be very poor fit in other environments. Unfortunately, there is no mention of this crucially important fact at all.
In addition, docs say that you can change the number of threads in Dispatchers.IO, but there is nothing about when you might want to do this. Oddly, there are two different mechanisms that limit the number of threads. Lastly, there is a surprising recommendation about using a custom dispatcher if you need more threads than the second threshold. It’s surprising because it makes it obvious that this dispatcher is a bad solution at least in some cases, but the docs don’t make any attempt to explain why.
So, the big questions in the context of Dispatchers.IO are:
- How exactly the limit of 64 threads benefits the users of this library?
- What are the trade-offs associated with the “size” of
Dispatchers.IO? - Why there are two different mechanisms that limit the size of the backing thread pool?
- What are the benefits of switching to a custom dispatcher if you need more threads?
Please note that these questions aren’t some abstract theoretical concerns. These are very practical considerations that you need to take into account to ensure not just performance, but even the basic correctness of your code (more on correctness later).
All in all, there is nothing simple or evident about either Dispatchers.Default or Dispatchers.IO. In this section, I simply quoted the official documentation and pointed out several “interesting” questions. In the next sections, I’ll provide my opinion on these issues and explain why you shouldn’t trust these dispatchers.
Why Dispatchers.Default is Believed to Be a Good Fit for CPU-Bound Work
As we’ve already seen, there are no specific guidelines regarding the usage of Dispatchers.Default in the official docs. Well, at least none that I found, even after investing a non-reasonable effort into the search. Therefore, just formally, there is no reason to use it at all. It sounds crazy, but if you just look at the dry facts, that’s what it is.
However, if that’s the case, then where does the widespread assumption that Dispatchers.Default should be used for CPU-bound work comes from? After all, that’s what countless articles (including some Android’s official docs) recommend. Is it probable that so many authors accidentally misinterpreted the official docs in exactly the same manner? Of course not.
In my estimation, the de-facto guidelines for this dispatcher simply “carried over” from RxJava’s Schedulers.computation(). Its documentation explicitly describes when you should, and when you shouldn’t use that scheduler:
Returns a default, shared
Schedulerinstance intended for computational work.
This can be used for event-loops, processing callbacks and other computational work.
It is not recommended to perform blocking, IO-bound work on this scheduler. Useio()instead.
The above quote is the exact explanation of Dispatchers.Default that you’ll find everywhere on the internet, except, once again, in Kotlin’s official documentation. Now, assuming that RxJava is indeed the source of that widespread assumption about Dispatchers.Default, it becomes important to understand why exactly this “carry-over” took place.
The reason for “carry-over” is simple: both Schedulers.computation() in RxJava and Dispatchers.Default in Coroutines are backed by NUM_OF_CPU_CORES threads. So, there is something about using as many threads as CPU cores that makes a thread pool suitable for CPU-bound work. [In practice, that’s not exactly accurate because the number returned by Runtime.getRuntime().availableProcessors() can differ from the number of physical CPU cores. However it’s convenient to just speak about CPU cores and the difference is irrelevant in most cases]
Of course, the above explanation leaves us with the next logical question: why this size of a thread pool is optimal for CPU-bound work?
The Connection Between CPU-Bound Work and the Number of CPU Cores
Let’s define the term “CPU-bound”.
There are tasks (work) that have the following property: their total execution time is dominated by the time spent executing instructions inside a CPU. In these cases, the execution time of the tasks will be bound from below by CPU’s “speed”, so we call them “CPU-bound”.
Consider, for example, complex mathematical computation that takes several seconds to complete. To execute this task, the system will probably need to read some data from the memory ahead of time, and then write some data into the memory upon completion, but most of the time will be spent on operations inside the CPU. Since the execution time of this task will be determined by the “speed” of the CPU, it’s CPU-bound. In essence, CPU-bound tasks “want to consume” the entire processing power of a CPU when they execute.
Modern CPUs have multiple cores that can execute tasks at the same time. In other words, modern CPUs can execute up to NUM_OF_CPU_CORES tasks in parallel. Therefore, if you imagine a system where many CPU-bound tasks are waiting for execution, the “fastest” way to execute them is to utilize all cores at once.
That’s where the idea of using a thread pool with NUM_OF_CPU_CORES threads comes from: this ensures that all cores will be utilized at maximum load (as long as there are CPU-bound tasks left to execute). If you use fewer threads, one or more CPUs can remain “unloaded”, reducing hardware utilization and delaying the completion of the batch of tasks. If you use more threads, you won’t utilize cores above 100%, but they might waste some cycles on context switches between excessive threads, so the overall time to complete all tasks might grow.
All in all, looks like using NUM_OF_CPU_CORES threads in a thread pool yields the best performance for CPU-bound tasks. That’s why RxJava’s Schedulers.computation() was configured this way and that’s why it was very natural to assume that Dispatchers.Default is a good fit for CPU-bound work, even though the official documentation never stated that.
Here is the thing, though: this picture is so incomplete, that it’s simply dangerous and harmful.
The Devil is in the Details
Let me demonstrate you the problem using an intuitive example first, and then we’ll discuss it in more detail.
Imagine an application that occasionally needs to process user’s images in background. Let’s assume that each image takes 100 ms to process and each “processing batch” contains 100 images. That’s definitely CPU-bound work. [In fact, the exact nature of the work and the time it requires aren’t that important, but these details will make the example more “real”]
So, somewhere inside your app you’ll have this piece of code (or similar):
public fun processImages(images: List<Image>) {
for (image in images) {
coroutineScope.launch(Dispatchers.Default) {
processImage(image)
}
}
}
private fun processImage(image: Image) {
// long running image processing algorithm
}
The total CPU processing time will be around 10 seconds per batch, but since Dispatchers.Default uses all CPU cores, the real time will be reduced by a factor of NUM_OF_CPU_CORES. For example, on a device with two cores, you can expect each batch to be processed in 5 seconds.
So far, so good. We obtained “optimal performance” for our image processing in background feature. However, now consider the fact that Dispatchers.Default is also used in other places in your app.
For example, imagine that while the image processing is in progress, user clicks on a button that invokes the following use case:
class ProcessDataUseCase {
public suspend fun processData(data: ComplexData): Result = withContext(Dispatchers.Default) {
val result;
... very complex CPU-bound data manipulation
return@withContext result;
}
}
What happens now? Well, on a device with two CPU cores, the user will wait for the result of this use case for up to 5 seconds (because Dispatchers.Default is saturated with image processing), plus the time it takes to actually process the data. Oops.
This unit test demonstrates the problem. “User action” will always take ~10 seconds to complete, even though it might look like it should be executed almost immediately:
@Test
fun longLatencyForUserOnDefaultDispatcherTest() {
runBlocking {
val coroutineScope = CoroutineScope(EmptyCoroutineContext)
val startTime = System.currentTimeMillis()
// use unconfined dispatcher to make sure that all "background"
// tasks submitted before user action
val backgroundJob = coroutineScope.launch(Dispatchers.Unconfined) {
// simulate background processing of images
repeat(Runtime.getRuntime().availableProcessors() * 100) {
launch(Dispatchers.Default) {
// simulate algorithm invocation for 100 ms
// (fake load just to avoid elimination optimization by compilers)
val finishTimeMillis = System.currentTimeMillis() + 100
var counter = 0
while (System.currentTimeMillis() < finishTimeMillis) {
counter++
}
if (counter > 250000000) {
println("wow, your device has really fast cores")
}
}
}
}
// simulate user action
val userJob = coroutineScope.launch {
println("user action")
}
backgroundJob.invokeOnCompletion {
println("background processing completed in: ${System.currentTimeMillis() - startTime} ms")
}
userJob.invokeOnCompletion {
println("user action latency: ${System.currentTimeMillis() - startTime} ms")
}
joinAll(backgroundJob, userJob)
}
}
}
The above examples show that I didn’t really obtain the optimal performance, but planted a huge time bomb of poor user experience inside my app, waiting to explode repeatedly at (seemingly) random times. Since the two features in question don’t even need to be related in any way (except the fact that both use Dispatchers.Default), investigating this kind of performance problems in bigger projects can be hell of a task.
And that’s far from being the only concern. In addition to performance degradation and poor user experience, usage of Dispatchers.Default can also lead to exotic problems like “thread starvation deadlocks”.
So, how comes that what looked like a strategy of optimal performance on the first sight, turned out to be dangerous time bomb in practice?
Premature Optimization
At this point, you clearly understand that something is very wrong with Dispatchers.Default and the “optimal performance” philosophy underlying it. However, it’s not that simple to diffuse this long-standing misconception. In this section, I’ll explain what’s the fundamental error here.
There is a book called Java Concurrency in Practice which is generally considered to be the “bible of concurrency” in JVM world. Consider this quote from that book:
Application performance can be measured in a number of ways, such as service time, latency, throughput, efficiency, scalability or capacity.
This single sentence pretty much explains why Dispatchers.Default was destined to fail. Using thread pool with NUM_OF_CPU_CORES threads doesn’t really yield the optimal performance, it just yields the best throughput, and even that only under very specific conditions. If maximal throughput is not your performance bottleneck, or the “ideal” conditions don’t exist, you shouldn’t use this dispatcher at all. But even if you do seek the best throughput, you still shouldn’t use this dispatcher (explained later).
I don’t want to go deeper into the “specific conditions” part, but, just to give you an idea of what I’m talking about, consider another quote from Java Concurrency in Practice:
For compute-intensive tasks, an N_cpu-processor system usually achieves optimum utilization with a thread pool of N_cpu + 1 threads. (Even compute-intensive threads occasionally take a page fault or pause for some other reason, so an “extra” runnable thread prevents CPU cycle from going unused when this happens).
In other words, NUM_OF_CPU_CORES might be optimal only for “pure CPU work” — a condition which probably doesn’t exist in real-world software.
So, the fundamental error in Dispatchers.Default (and Schedulers.computation() in RxJava) was to erroneously assume that throughput is the only performance metric of interest. In practice, in many (probably most) systems, throughput is not an issue at all. This is surely the case for absolute majority of GUI applications out there (e.g. Android). By pushing developers to optimize for throughput, authors of these frameworks made them sacrifice much more important aspects like correctness, latency, simplicity and others. On a very big scale.
Or, in the words of Java Concurrency in Practice:
It is therefore imperative that any performance tuning exercise be accomplished by concrete performance requirements (so you know both when to tune and when to stop tuning) and with a measurement program in place using a realistic configuration and load profile. Measure again after tuning to verify that you’ve achieved the desired improvement. The safety and maintenance risks associated with many optimizations are bad enough – you don’t want to pay these costs if you don’t need to – and you definitely don’t want to pay them if you don’t even get the desired benefit.
In other words, even for CPU-bound work, optimizing for throughput might not be required at all. In these situations, using Dispatchers.Default opens your application to very serious risks for no gain at all.
For example, in the earlier example of background images processing, depending on additional factors, using single-threaded executor could very well be the best choice.
Wrong Performance Optimization
In the previous section I explained why the attempt to optimize for throughput was premature optimization. However, there is even bigger problem here because Dispatchers.Default also constitutes wrong optimization strategy. The term “wrong” here means that, even assuming you would want to optimize specific concurrent CPU-bound flow in your app for throughput, using Dispatchers.Default is a bad choice that puts your application at risk.
You’ve already seen one example of what I’m talking about here earlier, when user-initiated flow was “stuck” for a long time due to ongoing processing in the background.
Fundamentally, the problem here is that when multiple flows share the same dispatcher, they automatically become coupled. In some cases, this coupling is safe. However, in case of Dispatchers.Default, which is limited to NUM_OF_CPU_CORES threads, this coupling can lead to performance and liveness problems.
At this point, you might wonder why I talk about Dispatchers.Default specifically. After all, clearly, the same issue can happen even with a standard thread pool having the same limit. Sure, every time you use bounded thread pool, you need to think about the implications, but Dispatchers.Default is unique in this context because you simply can’t analyze the implications.
See, the articles on the internet recommend using Dispatchers.Default for all CPU-bound work. Yes, the same dispatcher for everything. Furthermore, Coroutines framework automatically uses this dispatcher if you don’t specify another one explicitly. Therefore, even if today your code is safe, a week from now another developer might use Dispatchers.Default in completely unrelated part of the app and break your feature. Good luck debugging this problem. That’s basically the invisible coupling rearing its ugly head.
Going back to manually created thread pools. Yes, they are subject to the same problem. However, in most cases, developers wouldn’t use the same thread pool limited to NUM_OF_CPU_CORES threads for everything. Instead, they’d create a dedicated thread pool per each “type of tasks” in their app. This way, different flows wouldn’t be coupled together through a single thread pool. That’s a standard procedure among backend folks. [This is very simplified description, but the details aren’t important because I don’t intend to exhaust the topic of concurrency performance optimizations in this post]
So, not only Dispatchers.Default constitutes premature optimization, it’s also the wrong approach to use even when you do need that last bit of throughput.
Dispatchers.Default Considered Harmful
Let’s summarize why you should avoid Dispatchers.Default:
- Using a single bounded thread pool to execute many unrelated flows presents a risk of performance and liveness problems. The magnitude of this risk is inversely proportional to the number of CPU cores, which means that users with “weaker” devices are more exposed to it.
- There is no need to optimize for throughput in absolute majority of the cases (even if you do need to execute CPU-bound tasks), so that’s just premature optimization.
- This dispatcher is poorly named and poorly documented (compared to, for example, RxJava’s
Schedulers.computation()).
All in all, as I already said, using Dispatchers.Default inside your code is akin to planting a time bomb.
At this point, you might wonder why that’s the first time you hear about the danger of this dispatcher. After all, there is no shortage of projects that already use it in production. How comes they don’t experience problems? Well, I’ll need to speculate to answer this question, but I believe there are three factors at play here:
- Kotlin and, especially, Coroutines aren’t that popular outside of Android world. Furthermore, many (most?) backend frameworks rely on application servers or servlet containers for basic threads management.
- Absolute majority of projects don’t need throughput optimization. For example, Android applications rarely-ever execute any appreciable concurrent CPU-bound load. In these projects, even if
Dispatchers.Defaultwould be single-threaded, they wouldn’t probably notice the difference. - In my experience (limited to Android applications), most projects don’t notice performance degradation for a long time (mostly because they don’t measure performance), and they’re even slower to fix them. When I talk to potential clients, it’s not uncommon to hear: “our app is slow [sometimes takes too long to start, hangs, not smooth, etc.], but we haven’t identified the problem yet”. It looks like most of the older applications suffer from some performance issues, but they aren’t investigated until they become critical. I’m sure that at least part of these cases can be attributed to usage of
Dispatchers.Default.
However, it’s not that important why we don’t hear about issues with Dispatchers.Default more often. Earlier in the article I demonstrated how simple it is to run into these problems, so it’s not a theoretical concern. The danger is very real.
All in all, in light of the above discussion, my recommendation is to avoid Dispatchers.Default at all costs.
Dispatchers.IO Considered Harmful
If you follow my recommendation to avoid Dispatchers.Default, the next reasonable thing to do seems to be using Dispatchers.IO for all background work (whether CPU-bound, IO-bound, or otherwise). However, this would constitute just another unfortunate approach.
First of all, Dispatchers.IO has “loaded” name and its documentation reflects that. Therefore, if you’ll start using this dispatcher for CPU-bound work and in general code, this might confuse future maintainers.
However, the real problem is that, just like Dispatchers.Default isn’t a good fit for CPU-bound work, Dispatchers.IO isn’t a good fit for IO-bound work. I guess that’s another “you gotta be kidding me” point, so let me explain.
I remind you that Dispatchers.IO is limited to 64 threads. We’ve already discussed that there is no way this number will be optimal for all different JVM targets. That’s a red flag already. However, the real problem with the number 64 is that it’s simply unsuitable for IO-bound load. To explain why, let me go back to the fact that Dispatchers.IO has two distinct mechanisms for limiting the number of threads in it:
Additional threads in this pool are created and are shutdown on demand. The number of threads used by tasks in this dispatcher is limited by the value of “
kotlinx.coroutines.io.parallelism” (IO_PARALLELISM_PROPERTY_NAME) system property. It defaults to the limit of 64 threads or the number of cores (whichever is larger).
Moreover, the maximum configurable number of threads is capped by thekotlinx.coroutines.scheduler.max.pool.sizesystem property. If you need a higher number of parallel threads, you should use a custom dispatcher backed by your own thread pool.
Why use two different limits? Well, I can answer this question with a high degree of confidence because the second paragraph was added to the docs in response to the bug I encountered.
If you’re a long-time reader, you might remember this article that I wrote a year ago after the release of my Android multithreading course. In that article, which summarized my first extensive experience with Coroutines, I described a very strange issue that I ran into which caused Coroutines framework to “die”. I filed a bug report and, after some back and forth with one googler, he found the problem. Turned out that there was an undocumented hard limit on the number of threads in this dispatcher, which caused thread starvation deadlock in my (correct) code. Unfortunately, instead of fixing the problem, the maintainers decided to just document the second limit, so now this bizzare bug is part of the API. The fact that the second system property has completely unrelated name (hinting at, once again, RxJava origins) doesn’t help either.
All of that is water under bridge at this point, but it does emphasize a crucial limitation of Dispatchers.IO: it’s not safe to use this dispatcher for IO-bound work that contains inter-dependent tasks. Furthermore, this limit, if not changed (using two different mechanisms), will cause serious performance problems under high IO-bound load (which is common scenario, for example, in production backends). Sure, most Android applications will never hit the limit of this dispatcher, but why take the risk at all? Dispatchers.IO is misconfigured, its documentation is cumbersome and using it for non IO-bound tasks would be confusing for future maintainers. So, while this dispatcher is not as bad as Dispatchers.Default, it’s still pretty bad.
Therefore, I recommend avoiding Dispatchers.IO in your code as well.
Edit: in August 2022, Pierre-Yves Ricau from Square tweeted this screenshot:
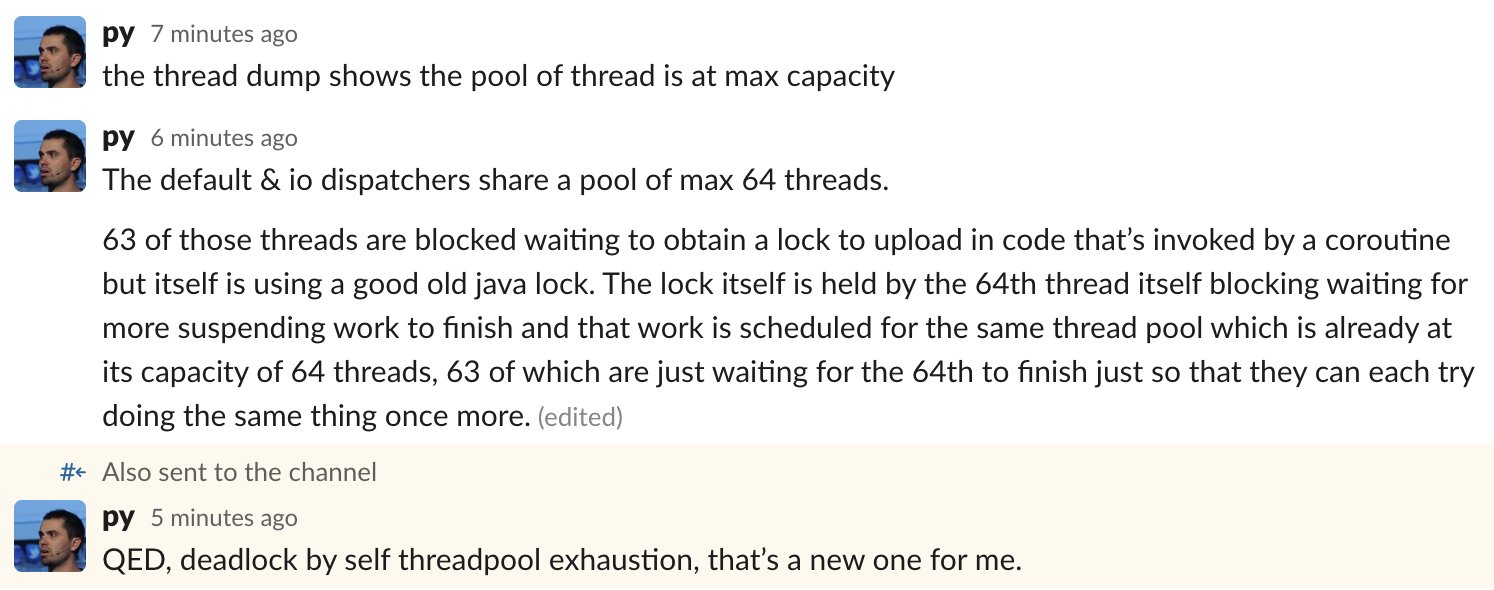
As you can see, folks at Square ran into exactly the problem I described above. Are they the only ones? Most probably, not. It’s just that Square, being the global powerhouse of Android development, has top developers who can investigate this issue and find its root cause.
The Best Dispatching Strategy for Android Applications
I’m not backend developer, therefore I can’t recommend any specific dispatching strategy to backend folks. That said, given the fact that requests usually reach backend logic on dedicated threads (handled by e.g. application server), I suspect that the need for additional multithreading can be relatively limited.
However, in Android applications, you can’t do anything of substance without offloading tasks from UI thread to background threads. Therefore, multithreading is everywhere in Android. If you use Coroutines (which I recommend if your app is purely in Kotlin), you need simple and robust dispatching strategy.
My recommendation is to use a single unbounded “background” dispatcher for all background work by default (regardless of whether this work is CPU-bound, IO-bound, or otherwise). And then, only if you see real performance issues, introduce additional dispatchers with different configuration for specific “types of tasks”. In practice, absolute majority of Android apps won’t ever need additional dispatchers.
You can find one potential implementation of “background” dispatcher in the tutorial code for my Coroutines Masterclass course. This dispatcher even includes extension function which will allow you to use it as Dispatchers.Background.
Some developers might feel uncomfortable using unbounded dispatcher because there are “all these potential issues”. In practice, I’ve been using unbounded thread pools for years and haven’t had any issues. That’s also the strategy implemented in my ThreadPoster library (which I recommend for projects written in Java). So far, there wasn’t a single complaint from its users. If you’re not convinced still, let me reference Java Concurrency in Practice once again:
The newCachedThreadPool factory is a good default choice for an Executor, providing better queuing performance than a fixed thread pool.
I decided to use unbounded thread pools following my own analysis of the requirements of a typical Android app, so it was relieving to learn that my own conclusion aligns with the recommendation from Java Concurrency in Practice.
The only situations I’ve ever encountered which required additional dispatchers were similar to our earlier example of image processing. In that case, you had CPU-bound background tasks that execute in a batch. If I’d just use my unbounded dispatcher, it would happily process these tasks. However, for several seconds (depending on the number of cores), I’d have up to 100 background threads which would compete with UI thread for CPU time. In this case, UI thread could become starved, which would lead to janky UI. That’s not good. Introducing standalone dispatcher for image processing resolves this problem. The size of that dispatcher would depend on the specific requirements and constraints of the app.
In summary: use unbounded “background” dispatcher for all background work by default; if you face real performance problems, introduce additional dispatchers for specific “types of tasks”.
Addressing the Initial Feedback
Following the initial feedback on this article (which I appreciate a lot, even if you disagree with my arguments), I realized that I chose a confusing example and it requires more explanation.
Earlier in this post, I explained how Dispathchers.Default can lead to serious problems in case of batch image processing in background. Then I recommended using unbounded dispatcher, but noted that it might not work properly in this scenario as well, so you’ll probably want to use a standalone dispatcher for that. Many readers asked a reasonable question in this context: “if neither Dispatchers.Default, nor unbounded dispatcher are optimal in this scenario, then what’s the difference?”. So, let’s discuss this topic in more detail.
With Dispatchers.Default, everything might work absolutely fine, until you submit one additional CPU-bound task for concurrent execution, and then everything breaks apart. “Breaks apart” here can be an excessively long latency for other, unrelated actions in the app (e.g. user navigates to another screen and then waits for seconds for locally stored data to be fetched). It can also be a complete deadlock, in case the tasks submitted for execution are not independent. In addition, since Dispatchers.Default is bounded, it enters the “risky area” once it needs to execute more than NUM_OF_CPU_CORES concurrent tasks. For Android apps, it means just 2 or 4 tasks in most cases. So, Dispatchers.Default can lead to abrupt, major failures, and the threshold of the risk is very, very low.
If you use unbounded dispatcher, the “failure mode” is completely different. First of all, unbounded dispatcher is protected against thread starvation deadlocks. This alone makes it much better choice for complex concurrent flows (as I demonstrated in another article, even Dispatchers.IO isn’t safe in this context). In addition, there is no “abrupt failure” with this dispatcher. The more CPU-bound concurrent tasks you submit for execution, the more likely you’re to starve UI thread. However, it’s not like at some threshold of tasks your UI will stop responding. Instead, the loss of responsiveness is a continuous function of the number of concurrent threads. Unlike with Dispatchers.Default, 2 or 4 CPU-bound concurrent tasks won’t be enough to put you at risk if you use unbounded dispatcher, so it’s much safer for absolute majority of Android projects.
Therefore, while it is true that submitting 100 concurrent CPU-bound tasks into unbounded dispatcher isn’t a good idea at all, for most practical purposes it will be much better suited and safer than Dispatchers.Default.
But that’s not all.
What many critics of this article miss is the fact that unbounded dispatcher replaces BOTH Dispatchers.Default and Dispatchers.IO. Imagine Coroutines framework where you have just one “background” dispatcher out of the box and you don’t need to waste your time on choosing which dispatcher to use. Such a configuration is much simpler for practical use, will be simpler to understand for new developers, won’t promote premature optimization mindset and will actually align Coroutines’ dispatchers configuration in JVM with the rest of the targets (Dispatchers.IO is unique to JVM). Therefore, even if you don’t “buy” my arguments against Dispatchers.Default and Dispatchers.IO individually (which I find odd, given the problems are demonstrated in “benchmarks”), you’ll probably still agree that having two different dispatchers for no good reason is worse than one dispatcher that can do the job.
Lastly, I want to discuss “context switches”. See, a surprising number of developers criticized my proposal of unbounded dispatcher claiming that it will be problematic due to context switches. So, first of all, allow me to quote Java Concurrency in Practice again:
It is therefore imperative that any performance tuning exercise be accomplished by concrete performance requirements (so you know both when to tune and when to stop tuning) and with a measurement program in place using a realistic configuration and load profile. Measure again after tuning to verify that you’ve achieved the desired improvement. The safety and maintenance risks associated with many optimizations are bad enough – you don’t want to pay these costs if you don’t need to – and you definitely don’t want to pay them if you don’t even get the desired benefit.
What I want to say with the above quote is that just pointing out to context switches isn’t really an argument in a discussion of performance. It’s only if you can show that their impact is non-negligible that it becomes a valid criticism. And I can’t think of an Android applications for which the cost of context switching will be non-negligible factor. Therefore, if you want to discuss “context switches”, please make sure to support your criticism with a benchmark that demonstrates a practical concern.
For example, you can replace Dispatchers.Default with an unboudned dispatcher in the unit test that you saw earlier in this post:
val unboundedDispatcher = Executors.newCachedThreadPool().asCoroutineDispatcher()
If you do that, you’ll see that:
- Unbounded dispatcher solves the problem introduced by
Dispatchers.Default. - The cost of context switching is negligible.
In fact, when I invoke this benchmark with unbounded dispatcher on my computer, not only it fixes the latency of user action, but the test also executes much faster than with Dispatchers.Default. Surprise, surprise! One more demonstration why any performance discussion should be grounded in the actual measured results, and not in hand-waiving.
The Bigger Picture
In the previous sections I explained why both Dispatchers.Default and Dispatchers.IO are limited in technical terms. However, what bothers me the most, is the impact of this approach on the larger field of software development.
See, as someone who spends a considerable time creating educational content and promoting best practices, I’m just depressed to see how quickly an anti-pattern can spread in the minds of developers once it’s promoted by the official sources. Countless developers learn and use these approaches, give “correct but incorrect” answers on interviews, take pride in the fact that they “optimize their code”, while, in practice, they unknowingly follow an unfortunate practice.
The sole fact that there is “performance optimization” as part of framework’s API “promotes” premature optimization mindset. Countless developers waste their time reading and “thinking” about performance, while it’s irrelevant in absolute majority of cases. Times and again, we forget about Knuth’s “premature optimization is the root of all evil” warning and fall into the same old trap.
Therefore, unless what I wrote in this post is proven to be incorrect, I think JetBrains should fix this problem. It’s a bitter pill to swallow at this point, but the alternative of perpetuating bad practices is much worse in my opinion.

Kotlin Coroutines in Android Course
Master the most advanced concurrency framework for Android development.
Go to CourseConclusion
I understand that the premise of this post is surprising and can be hard to digest. It can be even harder to accept, but this isn’t my first time exposing the “official guidelines” as bad practices. I do hope that you found this article interesting, regardless of whether you agree with it or not.
That’s it for today and I’m eagerly waiting to read your feedback and criticism in the comments section below.

To be honest, at first I was sceptical about this post, but now that I’ve read it, I get your point and completely agree. Next time I use coroutines, I’ll be way more analytical about the implementation strategy.
What I notice is that Android devs will most of the time jump on the hype train without proper assessment of what is good and what is bad, mislead by the latest and greatest “best practices”. In that aspect, I find your posts to be very sobering and are much appreciated.
Thank you!
Thanks Denislav,
It’s relieving to hear that you found this post, which took horrendous amount of time to write, interesting.
I understand your point of view, but arguable I could say creating your own unbounded dispatcher, and using everywhere is in a way an early optimisation, as your program may never reach or suffer the bounds within Default and IO Dispatchers.
I must agree on the point of having your program measured, to understand your bottlenecks and the parts where demands more or less. And want to thank you on exposing these cases, so when analysing the program you can judge if your case fits on it or not.
A practice we already have in our projects, always gave the Dispatcher (or Schedulers with Rx), via DI, so we can reasonable easy change its implementation without having to change all places in our code.
Have to disagree with the part of not being at the documentation a recommendation for Default. The docs sometimes are confusing and misleading but could find the recommendation in https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-dispatcher/index.html
It says:
Again want to thank you for sharing this knowledge and for sure I will take account on those when analysing my code.
Hello William,
Thanks for sharing your opinion. I’m not going to argue against it, since you obviously read the entire article already.
The only thing I’d like to point out is that this is not “premature optimization” because: a) the concern here is not just performance, but also the actual correctness of the program b) using two different dispatchers is more complex than one, so, even if you don’t “buy” my other arguments, this is an improvement that you can’t argue against (I guess).
I agree it is premature optimization. You are arguing against the way “it is currently done” but changing it brings no benefit. You are stating your way is safer/faster, but there is no proof or to me, a good reason. I don’t see any thing being more correct with using one dispatcher for everything, in fact it will cause bottlenecks like your example. I also noticed an unsatisfactory (buggy) example you shared where a network request (
dataApi.fetchData()) does not use .IO. Network requests are in fact, IO operations. This should not be your leading example.> Therefore, even if today your code is safe, a week from now another developer might use Dispatchers.Default in completely unrelated part of the app and break your feature.
I don’t see how using Default for another CPU bound task will break your feature. It would be up to the developer to time this task appropriate to avoid overusing resources at certain times. If the developer uses the wrong dispatcher for IO operations (i.e. .Default when there is a .IO), that is a bug. Catch it. Not anything else. Certainly the naming is unfortunately, it should be called Dispatchers.CPU.
William also addressed the documentation concern you had. It is documented in the abstract class (CoroutineDispatcher), not https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-default.html
I would like if you highlighted the specific issue you faced more instead (your previous blog post from “last year” did not go into depth, and neither did the ‘youtrack’ issue. Jetbrains bug fix was done simply by introducing the concept of limit twice, but calling it something different: cap and limit. That’s not very nice to see.
Finally, you are also complaining about Rx, but don’t think you finish that battle/ explain enough there.
This is therefore, precisely the meaning of premature optimization. No benefit, but added cost (and also introduces. bugs), as developers will now need to understand this article (which is quite long/ complex). (sorry to be so harsh)
Very, very interesting post. It was on my reading list for a long time and I finally read it. I will definitely think differently after reading this.
I agree with the arguments here and with that that “best practices” are not always best practices. I also have hard time with things Google is recommending.
I knew it was such a simple issue that doesn’t exist. This blog post explains in much fewer words than here, why this article highlights an issue doesn’t exist: https://elizarov.medium.com/blocking-threads-suspending-coroutines-d33e11bf4761
You never replied to Ben Butterworth’s latest comment. I’d be intersted in why you used Dispatcher.Default for
dataApi.fetchData()which clearly is not CPU bound. And how your argument holds if you’d correctly used Dispatcher.IO to fetch from your API or if the method you called was CPU bound.Thanks for your post and looking forward for getting this clarified.
Hey,
Ben didn’t ask any questions. He just shared his opinion, which I believe to be wrong, but I’m not here to argue with my readers. However, since you did ask a question, I’ll answer it.
With the example I used I just wanted to show the potential problem with Dispatcher.Default, which is not something most developers are even aware of. You could say that you shouldn’t use this dispatcher in this manner, but it doesn’t really change the fact that the problem is there. If the name of this method bothers you (because it hints towards IO), then imagine that it’s called processData() and is used to perform very complex CPU-heavy manipulation on a big set of data. That’s something you’d use Dispatchers.Default for, and the same risks of big troubles would apply. Therefore, the names there aren’t really important. Ben just pointed out to irrelevant detail.
I know that the argument I made in this post is very complex. If it wouldn’t be complex, chances are that Coroutines framework wouldn’t have this flaw. Therefore, I invite you to look at the bigger picture, which mostly boils down to three fundamental questions:
1. Do we really need to optimize for CPU-bound load in Android apps?
2. Even if we do want to optimize CPU-bound load, is using a single bounded dispatcher for everything is the proper approach?
3. What are the practical downsides of using a single unbounded dispatcher for everything by default?
My goal in this article was to demonstrate that when you really dig into these questions, the approach recommended by the official docs turns-out to be preliminary optimization and, furthermore, an incorrect one.
P.S. I changed the example in the post to avoid distracting readers with small details. Now the example should be much clearer. Thanks for bringing that to my attention (and thanks to Ben too).
Well, that was a very nice read and it provides a safe, clear, documented and, above all, it provides a turnkey solution. Unit testing included.
And yes you are right, especially if one faces a huge application, the complexity and subsequently the probability that things go south is very big indeed.
Thanks a lot!
Sorry but i really don’t get the point. In your test, at the end, you are using joinAll(backgroundJob, userJob) , and of course it waits also for backgroundJob that is a very long computation. But if you wait only for userJob you will see it completes very fast if you also replace Dispatcher.unconfined with Dispatcher.Default (Dispatcher.unconfined can provide side effects as stated from the documentation and the use is discorauged). So in a normal use case without using Dispatcher.unconfined the user will not wait long to see its action being completed. Am i missing something?
Hi,
The test case in the article aims to simulate the following scenario: your app starts batch image processing, and then the user performs some action. If you replace Unconfined with Default when starting the simulated load, this is a different scenario: user action happens before all images have been submitted for processing.
So, Unconfined dispatcher is used to simulate a real-world situation here. Therefore, it’s not a matter of “a normal use case” of coroutines, but what kind of scenario we’d like to simulate. Since I wanted to show an edge case when Default dispatcher causes long latency on user action, I chose a specific implemenation.
Ok, i am seeing your point now, but if you use Dispatcher.Default the user action isn’t started for first it is just asynchronous with the image processing, since it is another coroutine and uses another thread pool, as you can see if you put a delay before the user action some image processing is done. That would be a real world scenario, some image processing is done by the application when the user presses a button, for example, in the middle of processing. Instead, If you really want that image processing is done previously before any user action i guess you have to freeze the ui with a progress bar since you don’t have to interact while the image processing is happening as stated by this use case. Let me know if I am still missing something or misunderstanding your intentions.
I’m not sure what you’re trying to say. The example in the post shows how latency-critical action initiated by the user is “stuck” behind lower-priority work due to reliance on Default dispatcher. This is a real issue (though rare) that can happen in production. The root cause of the problem is also explained (single, small thread pool shared among unrelated flows). A solution is demonstrated.
Is there a mistake?
No, not a mistake. Your example works as expected but maybe I was wrong to think that it was a general case, as you stated it is a rare case that can happen. I would be curious to know if it can happen also without the use of Dispatchers.Unconfined. Thank you for your replies.
I have a question, I have read your article but I would like to know if these points are still active in the version for https://blog.jetbrains.com/kotlin/2021/12/introducing-kotlinx-coroutines-1-6-0/
Hey,
My points are still relevant because they haven’t changed anything about the recommended dispatchers, or their configuration.
It seems to me that the problem with the image processing example is that it’s using an unbounded queue of tasks and stuffing all the image processing tasks in at the same time, which results in the ProcessDataUseCase task (being last in the queue) ending up with too many queued tasks ahead of it. You propose, if I understand you correctly, that we assign more threads to consuming the queue, which will let it empty faster and reduce latency, at the cost of efficiency (because more worker threads compete for CPU and use more memory).
But isn’t the real problem the management of the queue? Ideally each core should be running a single worker thread, processing one task at the time, and it’s just a matter of deciding which task should be next in line for processing. In the image processing example, we decide that it should process all the image tasks first (by stuffing them all in the queue) and the ProcessDataUseCase last (by putting in last in the same queue), but it isn’t actually what we want.
Couldn’t this be solved using CoroutineDispatcher.limitedParallelism (which I haven’t tried) to limit the number of queued image processing tasks? The documentation even uses image processing as an example:
https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-dispatcher/limited-parallelism.html
And regarding liveness problems with inter-dependent tasks… I understand how this could be a problem if the tasks wait for each other by blocking the worker thread, but is it still a problem if the block by suspending the coroutine, i.e., essentially just registering a callback? Wouldn’t that free up the worker thread and prevent liveness problems?
What it is strange about this documentation you mentioned, is that it says at the end:
“Note that this example was structured in such a way that it illustrates the parallelism guarantees. In practice, it is usually better to use Dispatchers.IO or Dispatchers.Default instead of creating a backgroundDispatcher.”
Which leads to the original problem of using Dispatchers.IO or Dispatchers.Default that the author of this blog is discussing.
Thanks for sharing your thoughts Vasiliy. Your post was written in 2020 but is still relevant today. I very much align with your arguments against Dispatchers.IO, like you I also don’t get what it means to say that we have a limited thread pool that we use to execute BLOCKING operations. On the other hand, on your arguments about Dispatchers.Default I actually disagree and I think the points you make have more to do with coroutines and cooperative scheduling in general.
Essentially: coroutines & cooperative scheduling only works if you really only use code that correctly yields, or suspends in Kotlin terms. It’s not a fool proof technique and requires the engineer to have a good understanding of the code they execute on that runtime, be it their own or 3rd party. If not, then it’s a risk & a ticking bomb like you said.
With that in mind and reflecting back on your examples, if I had the image processing & very complex CPU bound tasks in my real app, and I use coroutines, my first attempt would be to update my code to yield, and I will probably make my less critical CPU-bound code (image processing) yield more, and make my more critical CPU bound tasks (user stuff) yield less if at all. That actually gives you, the application developer, much more control. At the end of the day, you only have X cores to execute code, by using preempted threads, every one of your tasks will make progress at some rate defined by your operating system.
Cooperative scheduling gives you more control, and more responsibility.
I think the argument that they were trying to make was primarily centred around the documentation which seems to mislead the developer. I agree with your thoughts – there needs to be coorperative scheduling, greedy coroutines need to yield in practice. That being said, I have seen people using Dispatchers.Default because the documentation seems to imply if the task does not have any IO operations involved, use the Default dispatcher.