
It’s always exciting to start a new Android project. You get to write the application from scratch and unlock its full potential. It’s also an opportunity to reflect on your past experience and evaluate your prior technical practices.
However, while preparing for a new adventure, you should always keep one universal fact in mind: you can’t get everything right. Your understanding of the requirements is incomplete at this point (if there are any requirements at all), and the requirements will also change as you go. You don’t know which technical and technological limitations you’ll run into. You can’t control or even just supervise your colleagues. And much more. In short: don’t be too stressed about how you start a new Android project. Chances are that most of your decisions don’t matter too much and you’ll need to figure things out as you progress.
However, there is a small subset of decisions which you’ll need to make early into the project which are actually important to get right. You need to know about these decisions and understand the trade-offs they involve. Otherwise, you can unintentionally undermine your new project.
In this post I’ll share with you my own list of the most important decisions you need to make when you start a new Android project and describe their respective trade-offs.
Dependency Injection
Dependency injection infrastructure should be the very first code that you add to your new Android project. Period.
In my opinion, DI is the most fundamental and one of the most beneficial architectural patterns in object-oriented design. By implementing proper DI in your codebase, you invest into long-term quality and make it much easier to expand and maintain the application. This effect lasts for the entire lifespan of the project.
So, why is it so important to set up DI on day one? Because it will be much, much harder to add DI to your codebase later, after you write any code. And the more code you have, the harder it will become. Introduction of DI into existing codebase usually requires major refactoring which is risky for the business and consumes much time. Therefore, if you don’t set up DI from the onset, chances are that you deny your application the benefits of DI forever.
The only trade-off that you need to take into account in respect to DI is the initial ramp-up time. I’m not talking about coding time – it takes less than a hour to set up DI on a greenfield project when you know what to do. So, lines of code aren’t the issue. However, it can take a considerable amount of time to actually learn what DI is and how to use it. Especially in Android, where the official guidelines equate DI with Dagger 2 DI framework and the documentation of the later became a meme among developers.
So, I highly recommend using DI in your new Android project, but be prepared for a steep learning curve if you haven’t used it before. This curve is so steep that you might want to pass on DI if that’s your first Android application and you don’t have anyone more experienced on the team.
Decoupling of UI Logic
Making sure that your user interface logic is decoupled from the rest of the app is the best investment into long-term maintainability of your codebase. In my experience, spaghetti of UI, application and business logic is the #1 problem in Android applications.
The reason you’d want to have UI logic decoupled is due to its very special characteristics, which are very different from the characteristics of other types of logic. Let me list some of them:
- UI logic usually has the most detailed and accurate requirements (UI mockups)
- Rate of change of app’s user interface is usually much higher than that of other app’s parts
- UI logic is unreadable in a sense that you can’t read the code and understand how app’s UI looks and behaves
- Most of the ugly hacks and workarounds in Android apps are related to the user interface code
- You can easily test UI logic manually
- It’s extremely difficult to test UI logic with automated tests
Some of the above characteristics are positive, while others are negative. By having this logic decoupled, you mitigate the impact of negative characteristics (e.g. poor automated testability) and maximize the impact of positive characteristics (e.g. detailed requirements).
Architectural patterns that aim at decoupling of UI logic are called Model-View-X, where “X” gets substituted with some other word or combination of words. For example: model-view-controller, model-view-presenter, model-view-viewmodel, etc.
Most of MVx approaches are extremely similar and it’s not that important which one you’ll use. So, just pick one well documented pattern and roll with it. That said, I recommend that you choose a pattern which advocates for extraction of UI logic from Activities and Fragments. I explained why I think it’s the best strategy in this post from several years ago, and, more recently, in this talk at Droidcon Berlin 2018.
By the way, unlike dependency injection, you can start decoupling your UI logic at any time, even in existing codebase, because it can be done on screen-by-screen basis. You just adopt some MVx for new screens and, potentially, refactor the existing “messy” ones. That’s really good. However, the messy screens can be so messy that you won’t want to risk and refactor them. To prevent this situation and avoid being slowed down, you should adopt MVx from the very beginning.
I’m not aware of any trade-offs in this context. Decoupling of UI logic is the best technical practice to adopt on Android project and it’s not that difficult. The only complication is that there are so many MVx patterns out there that it might be hard to choose one. If that’s your problem, then go with “my” approach which I call MVC. As far as I know, it’s the most mature and the most documented pattern for Android development.
Decoupling of Networking Logic
Another type of logic that you’d want to keep decoupled from the rest of the application is networking logic.
Specifically, what you want to avoid at all costs is using the data structures that represent server API schema in the main body of your app. Instead, you should have at least two sets of data structures: one to represent network requests and responses, and another one to use inside the main body of the app. Some projects have additional sets of data structures for UI or local persistence, but that’s optional and not as important as decoupling of networking part.
The problem with server defined data structures inside the main body of your application is that you don’t control them. Backend folks do. Therefore, each time they’ll change server’s API, you’ll need to mirror these changes into all the parts of the app that make use of networking data structures. API changes always happen, even on the most well-managed projects. If you’re lucky, backend’s API will be properly versioned and you’ll be able to choose when and how to migrate. However, this won’t resolve the fundamental problem of coupling to data structures that you don’t own. You’ll still need to refactor all the logic which uses these data structures in your app. The worst scenario in this respect is when developers use networking data structures as persistence schema for ORMs. In that case, you will need to change the logic and, in addition, you might need to define database migrations. Not fun.
The trade-off here is that this decoupling requires more effort and can lead to a (false) feeling of waste of time.
See, initially, when you define the aforementioned sets of data structures, they will probably be identical. So, you might feel like you’re wasting time when you’ll be translating from networking layer into domain layer using absolutely identical data structures. This isn’t waste of time, trust me. It might take a month, half a year or a year, but any successful project reaches a point where these data structures diverge. And when this will happen, you’ll be very happy to have a clear boundary between them. You’ll be able to add the additional translation logic at this boundary and avoid server API changes to affect the internal structure of your application.
Package by Feature
Next on my list of important decisions for a new Android project is the structure of application’s top-level packages.
For some reason, our natural tendency is to group classes that have similar roles together, which leads to appearance of top-level packages named “activities”, “data”, “domain”, etc. This approach is called “package-by-type” or “package-by-layer”. Although very natural, package-by-type is not the optimal way to organize your codebase.
What you want to do is to group classes that constitute features together. In other words, you want to group together classes that have similar reasons for change. This approach is called “package-by-feature” and it’s considered to be superior to package-by-type. For a general explanation of why it’s important to package your application by feature, allow me to refer you to this article by Robert “Uncle Bob” Martin.
The below image shows an example of top-level packages structured according to package-by-feature guidelines. I took it in one of my freelance projects.
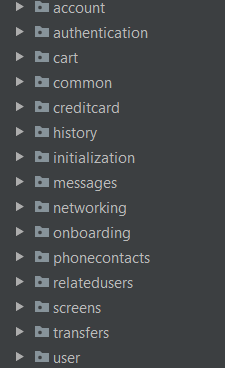
Note that just by looking at the names of top-level packages, you can make educated guesses about the functionality of this application. Furthermore, if you’d need to take over and maintain it going forward, you’d have relatively easy time mapping application’s features to the source code.
There is one additional advantage of package-by-feature that is very important in Android.
See, as your application grows in size, you’ll probably want to divide it into multiple modules. Modularization is quite challenging task all by itself, but it becomes extremely difficult if you hadn’t managed inter-dependencies inside the codebase properly. By using package-by-feature approach, you make your top-level packages readily available for extraction as standalone feature modules. This will make your life much, much easier when you’ll need to modularize your application.
The reasons you’d want to use package-by-feature from the beginning is because it can be quite time consuming to refactor to this approach later. Furthermore, the sole fact that you’ll need to think about individual features will lead to more clearly defined responsibilities and boundaries inside your codebase.
As for trade-offs with respect to package-by-feature, I can’t think of any. Maybe just the fact that you’ll need to overcome your initial temptation to group components by type.
Unit Testing
Unit testing is tricky subject. On the one hand, it can be very beneficial in terms of design quality and long-term maintainability. On the other hand, however, it can become major time waster with no clear benefits.
In my opinion, one of the most important things to understand about unit testing is that it’s a hands-on skill. You can read a hundred articles and books about unit testing, but still be unable to unit test even the simplest classes. You learn unit testing only by actually testing increasingly difficult code. There are no shortcuts. Now, don’t get me wrong – it’s also important to learn the fundamental theory behind unit testing, but it just won’t be useful on its own.
I believe that it’s important to write unit tests from day one because it immediately brakes the mental barrier. It’s not uncommon to hear on Android projects: “we want to unit test in the future”, but this future never actually arrives. In my experience, you can unit test at least some portion of your code at any point and you don’t need anything special for that. If that’s the case, then it makes sense to write your first unit tests as soon as possible.
However, there is a trade-off in respect to unit testing.
If you don’t have much experience with unit testing and you try to use it extensively, you can actually hurt the project. First, you can waste lots of time, thus reducing unit testing’s ROI (or even making it negative). Second, you can write bad or unnecessary tests, which can be even worse than no tests.
To mitigate the risks associated with unit testing and avoid burnout, you should start small and humble. Don’t try to unit test all your code, and don’t try to unit test complex code. Instead, find clearly defined pieces of functionality that can be encapsulated into small classes and test these. I find various data format validators (e.g. user input, server responses, etc.) to be exceptionally good candidates for being unit tested first. Start with them and gradually expand the scope of the code you unit test.
The corollary to my advice is that you shouldn’t aim at achieving any specific coverage number. It’s meaningless metric. Instead, make sure that you write meaningful unit tests and that for each class in your codebase the following applies: either all class’ functionality is unit tested, or none of it is.
BTW, just to make it clear: whenever I say unit testing, I imply test-driven-development. In my opinion, you can’t sustain proper unit testing practice if you write the tests after the fact.
Kotlin or Java
There is a widespread opinion that if you start a new Android project today (Feb 2019), you should use Kotlin and there is no reason to choose Java. With all due respect to Kotlin fans and advocates, I disagree.
The very first question to ask in this context is: what language do you know the best? If you have 5 years of Java experience and you only tried Kotlin on toy projects (like me), then choosing Kotlin can lead to a major slowdown. Kotlin advocates claim that Kotlin is so much more productive than Java that it will pay off, but, as of today (two years after official adoption on Andorid), this claim hasn’t been supported by any data.
Furthermore, it looks like Kotlin support on Android is still not nearly as mature as Java support. Some of the potential issues are: slower build times, lack of support for incremental annotation processing, bugs (like this recent bug in AndroidStudio which affected both stable and canary versions for the past couple of months). So you can expect additional slowdowns due to these factors.
All in all, I’d say that it’s too early to claim that there is no reason to use Java on new projects. I myself chose Java for my last project after considering Kotlin, and I’m really glad I did. It turned out to be very challenging application with hierarchical FSM having 30+ states at its core, so I’m glad that I used language that I have years of experience with.
And the last point to take into account is this: you can always turn Java codebase into Kotlin. It’s not entirely automatic process, but there are tools that support this flow and you can expect them to become better over time. So, choosing Java today still leaves you with an option to have Kotlin only application in the future. I’m not sure that the reverse it true.
However, there is a trade-off here. Kotlin might become so mainstream on Android, that it will be difficult to find developers to maintain legacy Java project in the future. In addition, some developers might not want to work in Java right now due to multitude of reasons. However, these aren’t technical trade-offs, so it’s probably not up to developers to consider them and you should involve other project stakeholders in this decision.
Summary
In this article I outlined several decisions which are important to get right at the beginning of a new Android project. Some of them involve either little or no trade-offs, so they are no-brainers, while others should be evaluated very carefully.
Except for making these specific decisions, I’d also recommend that you use the tools you know best on new projects. For some reason, I see (in myself and others) a tendency to adopt new technologies and tools when starting new projects. I’m not sure why that’s the case, but I learned that it’s an unfortunate idea in general. You don’t know what issues and limitations new tools might introduce, and quite often you learn that too late into the adoption curve when there is no way back. It’s better to test new tools on isolated areas of existing projects to see how they perform over time, and only then decide to go “all in”.
Thank you for reading and, as usual, you can leave your comments and questions below. It would be great to hear which decisions you consider the most important to get right on new Android projects.

Great Article. Thank you
Enlightening… to say the least.
> it will be difficult to find developers to maintain legacy Java project in the future
Meaning higher salaries – yet another bonus point for Java. Although I’m using Kotlin in my last project because *I want to code the same app on iOS* using Swift. Basically, I use Kotlin as a gateway bridge to iOS development. Also additional language looks cool in resume – at least until you have to explain the difference between let, with, apply, run, also.
The difference between let, with, apply, run and also is just whether you see the object you’re calling the method on as
this(apply/run) or as a function argument (also/let), and whether the function returns the object it’s called on (apply/also) or potentially some different value (let/run).And of course,
withis justapplyexcept you pass the object to it for some reason.I think whether Kotlin slows you down is just a matter of practice, but that is true of any new tech that you need to learn and has at least some sort of ramp up time. Isn’t that the “claimed downside” of Dagger, too? The common answer to that being “it’s ok though because it pays off over time”.
Great article! But, I personally feel it’s a bit hard to build fast and rollout with all these things equipped especially in a startup. But, we implemented DI and package by feature earlier which will later help us to modularise as well as write test code.
It is hard especially with decoupling UI logic and Unit Testing. But it’s even harder to start Unit Testing in an existing project.
Would anyone be able to suggest me more blogs like this? I’d like to hear more subjective blogs about android development in general.